티스토리 뷰
들어가기 전에
안녕하세요, Shopping Service API팀 강희정입니다.
작년 여름쯤 입사하여 낯선 환경과 도메인에 적응하고, 새롭게 접한 기술들을 익혀 가느라 정신없는 나날을 보냈습니다. 업무가 어느 정도 적응되었나 싶을 겨울쯤, 저에게 굉장히 낯선 업무가 주어졌습니다.
Master/Slave 구조의 Redis에서 Cluster 구조의 Redis로 migration 되니, 관련 코드 작업을 진행해 주세요.
업무를 받자마자 저는, 이런 생각을 했던 것 같습니다.
큰일 났다. 하나도 모르겠는데 어떡하지?
전통적인 SQL 방식의 RDBMS만 사용해 본 제게 Redis는 굉장히 낯선 존재였습니다. Redis도 모르겠는데 Cluster 구조로 migration하라는 코드를 작성하라니, 어디서부터 어떻게 시작해야 할지 감을 잡을 수가 없었습니다.
이 글은 Redis의 R자도 모르던 개발자가 Redis Cluster 관련 작업을 진행한 내용을 바탕으로 쓰여졌으며, 비슷한 처지에 놓여 있는 주니어 개발자분들이 관련 작업을 진행하실 때 가이드라인이 되었으면 하는 바람입니다.
개발자가 해야 할 일에 대해 기술한 글로, Redis Cluster 인프라 세팅과 관련된 내용이 다소 부족할 수 있습니다.
(결론부터만 말하자면, 다행히도 사내 위키에 관련된 많은 정보가 있었고, 팀원분들과 관련 담당자분들의 도움을 받아 무사히 작업을 진행했습니다 🙂 )
그래서 Redis가 뭔데?
Redis를 모르는 상태에서 Redis 작업을 진행할 수는 없죠.
Redis 공식 홈페이지에 따르면, Redis는 오픈 소스 인메모리 데이터 구조라고 설명하고 있습니다.
인메모리(In-memory)란 이름 그대로 메모리 내에 있다는 뜻으로, 인메모리 데이터 구조란 메모리(RAM)상에 모든 데이터를 저장하고 가져다 쓰는 데이터 구조라고 할 수 있습니다. 익히 알고 있듯이, 디스크보다는 메모리가 훨씬 빠른 연산 속도를 가지고 있기에, Redis는 읽고 쓰는 연산이 많이 발생하는 상황에 효율적입니다.
또한 key-value 쌍으로 구성된 것도 Redis의 큰 특징 중 하나입니다. string, hash, list, set, sorted set, bitmap, hyperloglogs 등의 자료구조를 지원하고 있습니다.
이러한 특성을 바탕으로 Redis는 DB, 캐시, 메시지 브로커 등 다양한 곳에서 사용되고 있습니다.
로컬에 Redis 설치하고 실행하기
아주 기초적인 내용입니다. redis-cli가 무엇인지 아는 분들은 다음 섹션으로 건너뛰셔도 되며, 그렇지 않은 분들은 읽으시길 권장해 드립니다.
많은 회사에서는 Redis를 담당하는 팀이 따로 있어 개발자가 직접 서버에 Redis 구성을 하지 않을 수 있습니다. 아니면 잘 만들어진 docker-compose 덕에 redis 구성을 하지 않을 수도 있을 겁니다.
개발이나 테스트 환경에 올라가 있는 Redis를 자유롭게 조작할 수 있으면 좋겠지만 그러기에 쉽지 않고, 모든 회사의 인프라 담당자가 개발자에게 로컬 환경 세팅을 위한 docker-compose를 제공하진 않을 테니, 작업을 진행하기에 앞서 로컬 pc에 Redis를 설치하고 실행해 보도록 합시다.
Redis 다운로드 페이지 : https://redis.io/download/#redis-downloads
각자 로컬 개발 환경에 맞게 다운로드받되, 저희는 migration 작업을 지원해야 하므로 사내에서 사용하는 Redis 버전에 맞춰 다운로드하도록 합니다. 클라이언트 코드의 라이브러리 버전이 달라 곤란한 일이 발생하는 경우가 있어, 되도록 버전에 맞는 Redis를 설치하도록 합니다.
이 글에서는 Redis의 버전은 고려하지 않고 M1 macOS에서 tar.gz 파일을 다운로드 받는 것을 기준으로 말씀드리겠습니다.
다운로드 파일 압축 해제 → src 폴더 접근 → sudo make install을 통해 developer tool 설치를 진행합니다.

redis-server 커맨드를 통해 Redis 서버를 띄울 수 있으며, Redis의 기본 정보(버전, 포트번호, 서버 시작 시각)를 확인할 수 있습니다.
Redis가 실행되면 redis-cli를 통해 접속할 수 있습니다. (서버가 띄워져 있는 창에서 글자가 안 쳐진다고 당황하시면 안 됩니다. 다른 터미널 열어서 들어가야 합니다) Redis 상에서 여러 명령어를 실행하기 위해서는 우선 redis-cli에 접속해야 하고, 그 이후에 keys(모든 key를 가져오는 명령어)나 mget(key에 대한 값을 가져오는 명령어) 등 여러 명령어들을 사용할 수 있습니다. 이후 cluster 설정도 redis-cli에서 진행하므로, redis-cli를 실행하는 방법을 반드시 익혀놓으셔야 합니다.
로컬에 설치한 redis 외에 기존에 사용하고 있던 Master/Slave의 Redis도 redis-cli로 접속이 가능합니다. (Redis-cli 참고 문서)

실행시켰던 Redis를 종료하기 위해서는 redis-cli로 접속한 채 shutdown을 통해 Redis를 종료시킵니다. 이후 topology update를 확인할 때 사용해야 하므로 이 또한 기억합시다.

Master/Slave 구조와 Cluster 구조
Master/Slave 구조는 Master의 내용을 Slave에 복제하여 read/write 권한을 나눠 사용하는 구조입니다.
Cluster 구조는 여러 대의 Master를 두어 가용성을 높인 구조로, 하나의 Master가 fail 되면 짝을 이루고 있던 Slave가 Master로 승격되어 가용성을 보장하는 구조입니다. 일반적으로 Cluster 구조에서는 3개의 node를 구성해서 사용하고 있지만 경우에 따라서는 node의 개수를 변경할 수 있습니다.
Master/Slave 구조와 Cluster 간엔 여러 차이가 있지만, 아래 그림을 통해 개발에 필요한 내용만 간단히 짚고 넘어가겠습니다.
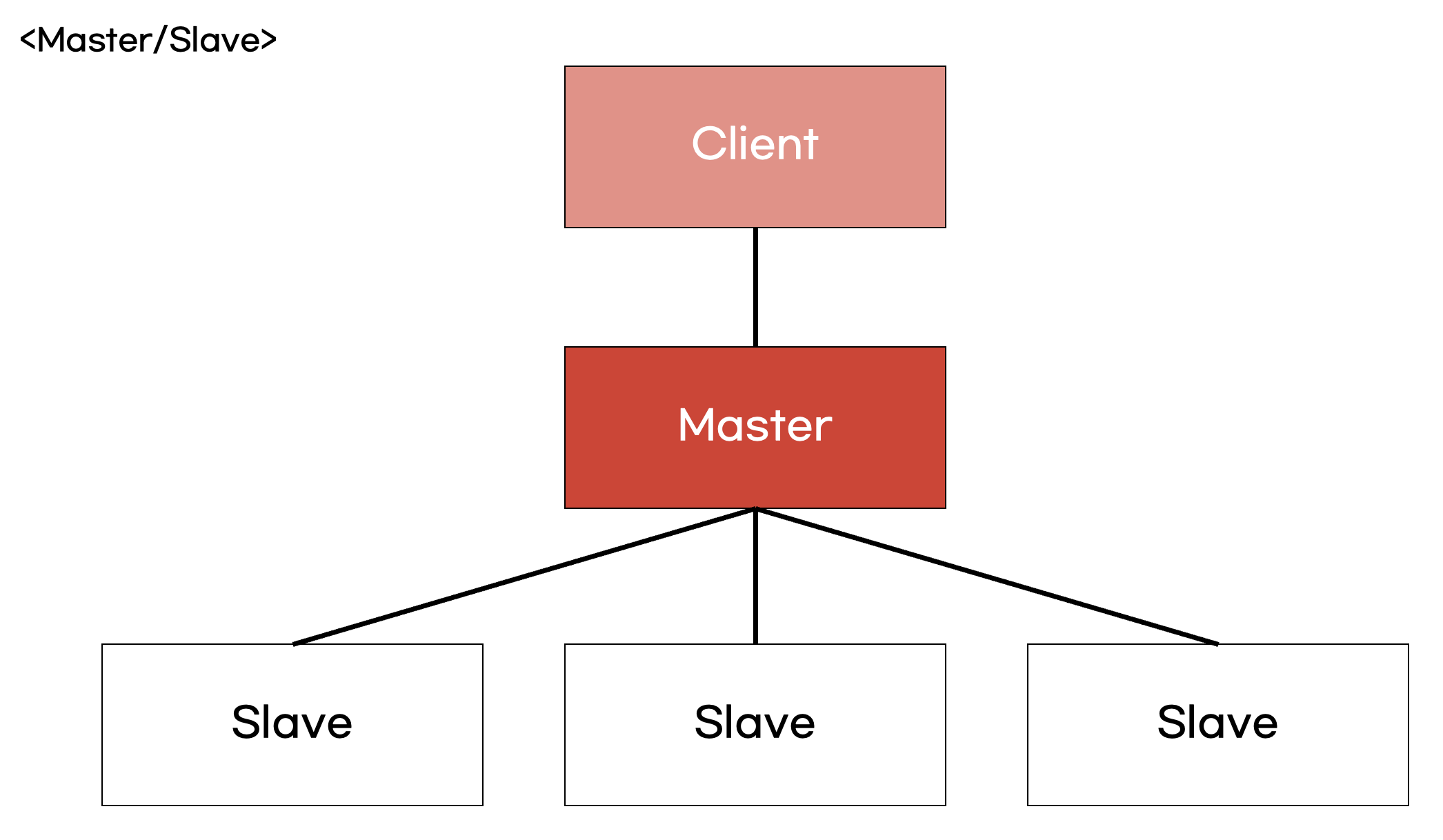
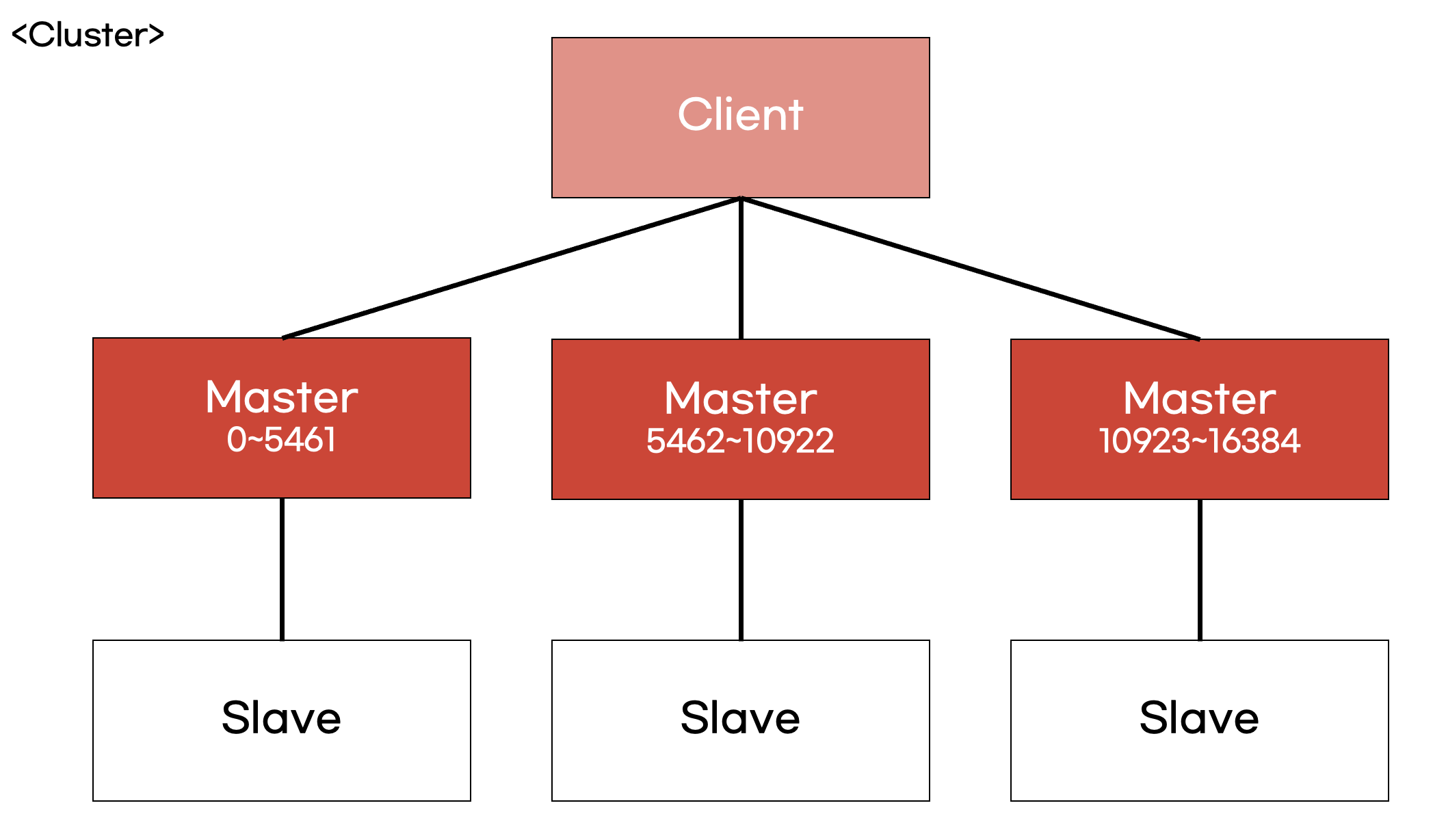
Master/Slave 구조에서는 어떤 key가 들어오든 간에 하나의 master에서 처리를 진행하지만, Cluster 구조에서는 key를 hash한 값에 따라 들어가는 master node가 달라집니다.
key가 정확히 어떤 알고리즘을 통해 나누어지는지는 Redis 공식 문서를 통해 확인할 수 있습니다.
즉, Master/Slave에는 모든 key가 한 node에 있고 Cluster는 그렇지 않은 상황입니다.
이에 따라 Redis를 사용하는 클라이언트 단에서 여러 문제점이 발생하고, 이 부분은 Redis를 구축해 주신 고마운 인프라 담당자분께서 해결할 문제가 아닌, 저희 개발자들이 해결해 나가야 할 문제입니다.
Cluster 전환 시 클라이언트 단에서 고려해야 할 부분
여기서 말하는 클라이언트란 Redis를 사용하는 코드를 의미합니다. 내가 아무리 백엔드 개발자로서 서버 코드를 다루고 있다고 해도, 이 서버가 Redis를 사용하고 있다면 클라이언트 코드에 해당하므로, 백엔드 개발자라고 해서 작업이 없으리라 생각하면 큰일입니다. (사실 모든 작업은 백엔드 개발자의 역할입니다.)
Java를 이용해 Redis에 연결하고 있다면 Java가 클라이언트에 해당하고, Node.js를 통해 Redis에 연결하고 있다면 Node.js가 클라이언트에 해당합니다. 즉, 클라이언트 단 작업은 코드를 수정하는 일이라고 보면 됩니다.
아래 기술된 내용 외 추가적인 고려 사항은 Redis 공식 문서를 참조하시면 됩니다.
클라이언트 라이브러리 확인
클라이언트 라이브러리는 코드에서 Redis를 잘 사용할 수 있도록 만들어 둔 라이브러리를 의미합니다. 웹 서버도 직접 소켓 프로그래밍을 통해 웹 서버를 만들어서 돌릴 수 있지만 굳이 그렇게 하지 않고 Apache나 IIS를 띄워 사용하는 것처럼, Redis에 연결하여 Redis 명령어를 사용하기 위한 연산자를 직접 만들어 사용하는 것이 아니라 일반적으로 클라이언트 라이브러리를 사용하여 Redis를 사용합니다.
보통 Java 기반 프로젝트라면 lettuce.io를, Node.js 기반 프로젝트라면 ioredis를 사용해 Redis에 연결합니다. 기존에 Master/Slave 구조를 사용하고 있는 상황을 가정하고 있으므로, 전환 대상의 프로젝트에는 위와 같은 라이브러리가 사용되고 있을 것입니다.
여기서 개발자가 고려해야 할 내용은 클라이언트 라이브러리의 버전 입니다.
Redis 3.0부터 Cluster를 지원하기 시작했고 클라이언트 라이브러리에 따라 Redis Cluster를 지원하지 않는 경우도 있을 수 있지만, 2023년인 현재 Redis 3.0은 너무나도 먼 과거의 이야기이므로 대부분 프로젝트에서는 큰 문제가 되지 않으리라 예상됩니다. 그래도 혹시 모르니까 확인해 봅시다.
사실 클라이언트 라이브러리의 버전은 Cluster에만 국한된 내용은 아닙니다. 조금만 다른 측면에서 생각해 보면, Master/Slave에서 Cluster로 이전하는 작업은 인프라 담당자 입장에서는 합법적으로 서버 OS 업그레이드 및 Redis의 버전을 업그레이드할 수 있는 절체절명의 기회이므로, 높은 확률로 OS 및 Redis 버전의 업그레이드가 일어나기 마련입니다.
OS 및 Redis 버전이 업그레이드되면, 관련된 클라이언트 라이브러리가 너무나도 높아진 OS와 Redis의 수준을 따라가지 못하는 상황이 발생할 수 있습니다. 따라서 클라이언트 라이브러리 버전 별 릴리즈 노트를 확인하여 지원하는 Redis 버전을 확인하여 작업을 진행하도록 합니다.
- lettuce.io 릴리즈 노트 : https://github.com/lettuce-io/lettuce-core/releases
- ioredis 릴리즈 노트 : https://github.com/luin/ioredis/blob/HEAD/CHANGELOG.md


위는 lettuce.io의 릴리즈 노트인데, lettuce.io 버전에 따라 지원하는 Redis 버전이 다름을 확인할 수 있습니다. 만약 기존 Master/Slave의 Redis 버전이 6 버전 대고 lettuce의 버전이 5.3.7이었다면, 신규로 발급받을 Redis 7 이상의 Cluster에서는 사용이 불가능한 상황이므로 클라이언트 라이브러리 업데이트를 진행해야 합니다. (그렇게 개발자는 의존성 지옥에 빠지게 됩니다…)
동시에 여러 key에 접근하지 않도록 하기
앞서 Cluster 구조에 대해 말씀드릴 때 간략하게 설명해 드린 내용이 있습니다.
Master/Slave에는 모든 key가 한 node에 있고 Cluster는 그렇지 않은 상황입니다.
이 특성은 Cluster로 migration 시 굉장히 중요한 고려사항이자 많은 개발자의 머리를 싸매게 할 특성입니다.
Cluster 구조에서는 key가 한 node에 있지 않고 여러 node에 분산되어 있는데, 그렇게 되면 동시에 여러 key에 접근하는 것이 불가능해집니다.
동시에 여러 key에 접근한다는 의미는 Redis 연산을 수행할 때 인자로 여러 개의 key를 넘기는 상황을 의미합니다. 대표적인 명령어로는 mget, mset을 예로 들 수 있습니다.
redis-cli에서 mget을 사용해 데이터를 가져오는 방법은 아래와 같습니다.
# redis의 현재 상황
# {key: key1, value: "first"}
# {key: key2, value: "second"}
redis-cli > SET key1 "first"
redis-cli > SET key2 "second"
# MGET으로 2개의 key에 대한 값을 동시에 가져옴
redis-cli > MGET key1 key2
1) "first"
2) "second"mget의 파라미터로 2개의 key를 넘겨주고 있는데, 코드에서 이러한 부분이 보이면 수정을 진행해야 합니다.
ioredis에서는 Redis의 연산자명 그대로 메소드명으로 사용하고 있어서 파악하기 쉽지만, lettuce.io에서는 Redis 연산자명 그대로 메소드명으로 사용하고 있지 않습니다.
lettuce.io에서는 RedisTemplate을 이용해 Redis를 연동하고 있는데, 관련 코드와 문서를 따라가 보면 Redis의 어떤 연산자에 해당하는지 확인할 수 있습니다.
// redis 연결
RedisTemplate<String, Integer> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
// keys : key들이 들어있는 ArrayList
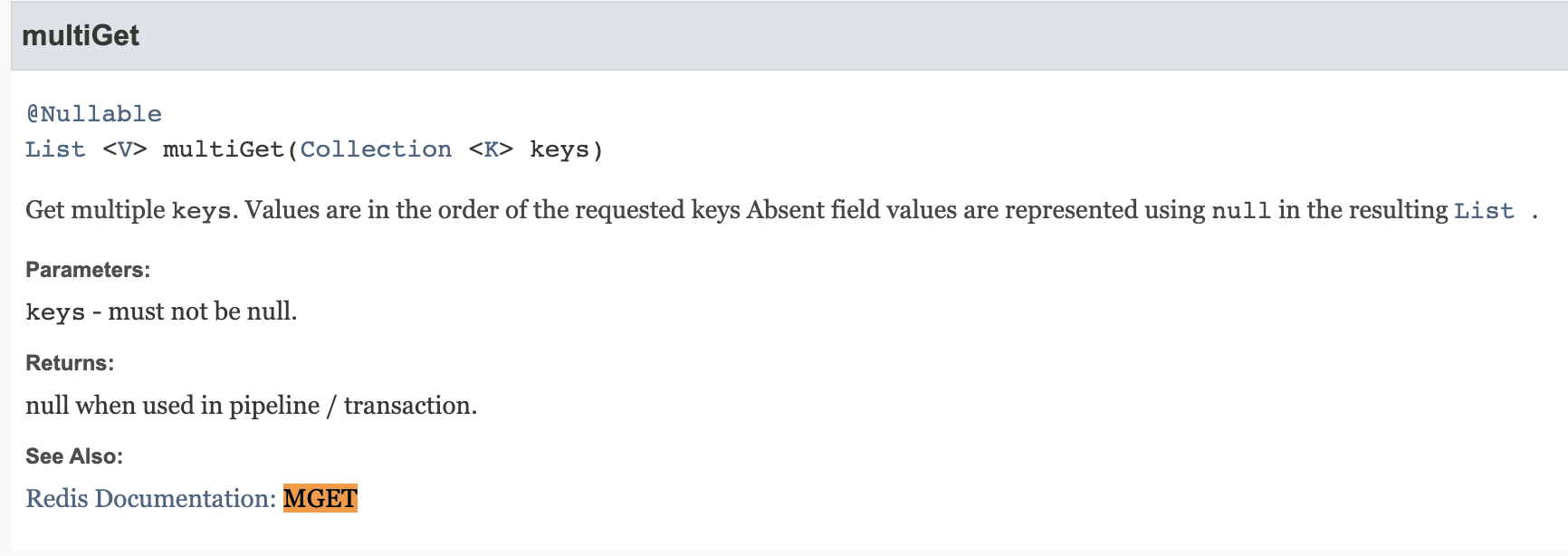
redisTemplate.opsForValue().multiGet(keys);IDE에서 multiGet에 커서를 두고 코드 탐색기를 통해 넘어가면 이러한 정보를 볼 수 있습니다.

주석으로 쓰여 있듯이, multiGet은 mget에 해당하고, 즉 우리가 바꿔야 할 메소드란 것을 확인할 수 있습니다.
또한 spring doc에서 메소드 검색으로도 확인할 수 있습니다.
여러 key에 접근하는 코드를 바꾸는 간단한 방법은 여러 key에 대해 반복문을 돌면서 하나의 key에 대한 연산을 개별적으로 진행하는 방법이 있습니다. 위의 예시라면 아래와 같이 변경할 수 있습니다.
// redis 연결 부분 생략
// keys : key들이 들어있는 ArrayList
for(var key : keys) {
redisTemplate.opsForValue().get(key);
}주의하셔야 할 점은, 여러 개의 key를 동시에 접근하는 연산이 mget과 mset만 존재하는 것은 아닙니다.
간과하기 쉬운 연산자로는 delete가 있는데, delete는 단일 파라미터와 다중 파라미터를 모두 처리할 수 있어 코드상에서 delete가 다중 key를 사용하고 있지는 않은지 면밀하게 살펴보아야 합니다.
var keys = new ArrayList<String>(); // 생성 후 element를 넣었다고 가정
var key = "key";
redisTemplate.delete(key); // cluster 구조에서 문제 없음 -> 변경대상 아님
redisTemplate.delete(keys); // cluster 구조에서 문제 있음 -> 변경대상delete의 경우까지 따져봤을 때, 동시에 여러 key를 사용하는 메소드를 판별하기 가장 쉬운 방법은 아무래도 메소드의 인자로 리스트가 넘어가는지를 확인하는 것이라 생각합니다.
트랜잭션 전면 재검토
동시에 여러 key에 접근할 수 없게 만들었던 원흉인 Cluster의 key에 따른 node 분배 때문에 신경 써야 하는 작업이 또 하나 생겨버렸습니다. 바로 트랜잭션과 관련된 내용입니다.
Redis는 SQL 기반 RDBMS처럼 연산들의 원자성을 보장하는 트랜잭션을 지원하고 있습니다. 주로 multi 연산자를 이용해 트랜잭션을 진행합니다. 하지만 이 트랜잭션은 같은 node 안에서만 실행할 수 있기에, key의 hash값에 따라 들어가는 node가 달라지는 Cluster 구조에서는 트랜잭션을 적용하는 것이 불가능합니다.
하지만 그렇다고 해서 트랜잭션을 포기하기란 어려운 상황입니다. 트랜잭션으로 연산을 묶어 놓은 상황이라면 중간에 유실되어서는 안 되는 중요한 작업일 텐데, 이렇게나 중요한 작업을 쪼개 놓는 것은 프로젝트가 제 기능을 하지 못하도록 막는 것과 다름이 없습니다.
다행히도 Redis는 트랜잭션을 할 수 있도록 나름의 방법인 hash tag를 제공하고 있습니다.
하나의 node에 몰아넣는 방법 - hash tags
Redis의 key를 중괄호로 묶으면, 중괄호 내의 key를 hash한 결과값을 바탕으로 node에 할당하게 됩니다.
- key:{group}:test
- key:group:test
- key:{group}:hello
여기서 group이라는 문자열이 중괄호로 묶여 있는 것을 확인할 수 있는데, 이를 hash tag라 합니다. hash tag가 없는 key는 key 전체를 hash하는 반면, hash tag를 포함한 key는 hash tag 내부에 있는 문자열에만 hash를 진행합니다. 따라서 같은 hash tag를 가진 다른 key도 같은 node에 들어가는 것을 보장할 수 있습니다.
예시로 확인해 보자면 1과 3은 {group}으로 hash되어 같은 node에 들어감을 보장할 수 있고, 1과 2는 각각 {group}과 key:group:test로 hash되어 같은 node에 들어감을 보장할 수 없는 상황입니다.
이 외에도 다른 여러 케이스가 존재하며, hash tags의 자세한 사용법은 Redis 공식 문서에서 확인할 수 있습니다.
hash tags는 트랜잭션뿐만 아니라 아래와 같이 동시에 여러 key에 접근하는 연산에도 적용하여 사용할 수 있습니다. 즉, 동일 node에서 돌아가야만 하는 기능들에 적용할 수 있습니다.
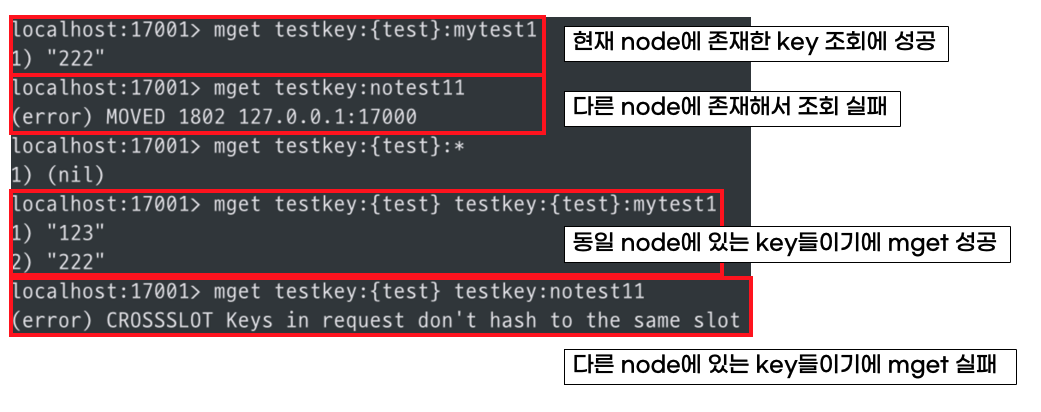
hash tag를 사용한다면 특정 key들을 묶을 수 있는 장점이 있지만, 그렇게 되면 여러 node에 분산되는 것이 아니라 하나의 node에만 집중될 수 있다는 단점이 있습니다.
Cluster 구조가 Master/Slave 구조에 비해 가지는 장점은 Master를 분산하여 가용성을 높인 것인데, 극단적인 경우를 생각한다면 하나의 node에만 read/write가 일어나는 경우를 생각할 수 있고, 기존의 Master/Slave와 달라질 것이 없는 상황이 됩니다.
따라서 hash tags를 활용할 때는 이러한 점에 주의해야 하며, 너무 과도하게 남발하지 않도록 합니다.
Cluster 서버 성능과 관련된 정보 확인
인프라 담당자가 아닌 개발자라 방심하고 있었지만, 개발자 또한 Cluster 성능에 신경을 써야 합니다.
앞서 설명해 드렸던 Hash tags의 예시와 같이 최악의 경우 하나의 node에만 몰리는 상황이 발생할 수 있으므로, 현재 기능을 옮겼을 때 migration되는 Cluster의 서버 성능이 이를 지원할 수 있는지 어느 정도 예측해 보아야 합니다.
현재 사용하고 있는 Redis의 성능은 아래와 같이 확인해 볼 수 있습니다.
- redis-cli > info를 통한 확인 - 현재 cpu를 얼마나 사용하고 있는지, 메모리를 얼마나 사용하고 있는지 등의 정보를 확인할 수 있습니다.
127.0.0.1:17000> info
# Server
redis_version:7.0.4
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:38e7ad9173e67551
redis_mode:cluster
os:Linux 5.15.49-linuxkit aarch64
arch_bits:64
...
# Memory
used_memory:3173000
used_memory_human:3.03M
used_memory_rss:10575872
used_memory_rss_human:10.09M
used_memory_peak:3314232
used_memory_peak_human:3.16M
used_memory_peak_perc:95.74%
used_memory_overhead:2763610
used_memory_startup:1633072
used_memory_dataset:409390
used_memory_dataset_perc:26.59%
...- redis-cli > --latency를 통한 응답시간 확인

- 해당 서버에 ping을 보내서 돌아오는 응답시간을 확인한 것으로, 강제 종료를 하기 전까지 계속해서 ping을 보냅니다. 반복해서 보낸 ping값의 평균값을 응답시간으로 보여줍니다.
이 외에도 여러 방법이 있을 수 있습니다. 하지만 여기까지 읽으신 분들이라면 조금은 의문점이 들 수는 있을 겁니다. 저 명령어들은 서버에서 직접 실행하는 것이고, 보통 운영 서버에 직접 접근하기는 어려워서 직접 확인해 볼 수도 없을뿐더러 --latency의 경우 서버에 직접 부하를 주는 행동이기에 섣불리 위 방법을 쓸 수 없을 것 같다는 생각이 드셨을 겁니다.
또한, 이미 사용되고 있는 서버의 정보는 확인할 수 있지만 migration 전까지 지급이 되지 않은 신규 cluster 서버의 used_memory나 latency 정보는 알기 어려운 상황입니다.
Redis의 성능을 직접 비교하기는 어려운 상황이라, 간접적으로나마 성능을 비교할 방법으로 Redis가 설치된 서버의 하드웨어 스펙을 비교하는 것을 택했습니다. Redis는 인메모리 데이터 구조이므로 메모리가 중요하다고 생각해 이 점을 염두에 두고 CPU 코어 수, RAM 크기, 디스크 크기 등을 비교하였습니다.
서버 스펙이 달라질 확률이 높으니, key size 확인이 필요할 수도 있습니다. RediSearch Sizing Calculator나 다른 공식 등을 통해 현재 사용하고 있는 key들을 Cluster로 옮겼을 때의 예상 size를 확인해 보아야 합니다.
Data Migration
Redis Cluster Migration 작업도 DB를 옮기는 작업이므로, 기존에 포함하고 있는 데이터를 신규 Cluster에 옮기는 작업이 별도로 필요합니다. 주기적으로 동작하는 job을 이용해 데이터를 만들고 있는 것이 아니라면, 신규 Cluster를 처음 받았을 때는 깡통처럼 빈 Redis가 올 것이기에, 별도로 데이터를 Migration 해 주는 작업을 진행해야 합니다.
로컬 환경에서 확인하기
Cluster 이전 관련 작업이 진행되었다면 개발 환경이나 운영 환경에 올리기 전에 로컬에서 테스트를 진행해 봅니다. 로컬 환경에서 테스트를 진행하려면 우선 로컬 환경에 Redis Cluster를 간단하게나마 구축해야 합니다.
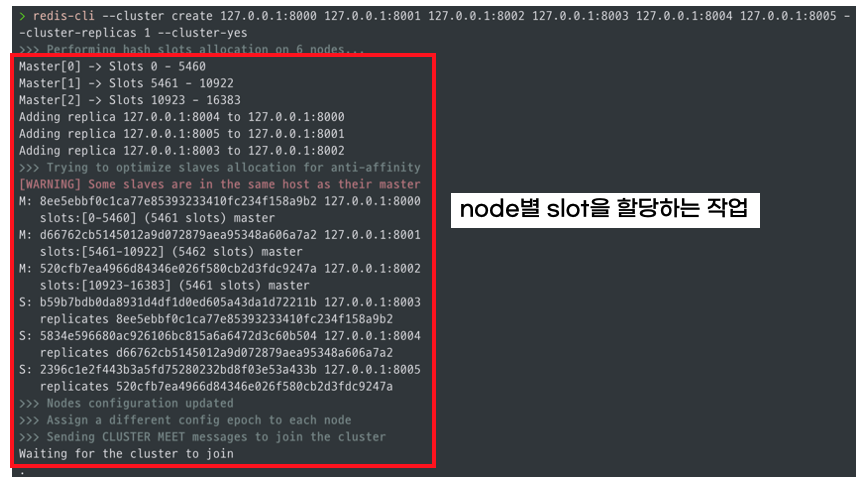
우선 아래와 같은 내용으로 6개의 파일(redis1.conf ~ redis6.conf)을 생성해 줍시다.
# M1에서는 7000으로 띄우면 기본 포트와 충돌이 날 수 있으므로 8000번으로 설정
port 8000
# cluster 사용 여부
cluster-enabled yes
# cluster 설정 파일 이름. 각 설정파일마다 포트번호 변경해주어야 함
cluster-config-file node_8000.conf
# timeout 시간 지정 (ms)
cluster-node-timeout 5000
# failover된 redis node 재실행 시 이전 데이터를 다시 로드해올 수 있음
appendonly yesredisx.conf는 Redis 실행 시 설정 정보를 담고 있는 설정 파일에 해당합니다. 구성한 설정 파일을 바탕으로 Redis 서버를 6개 띄워 줍니다.
#1번부터 6번까지 띄워준다.
$ ./redis-server redis1.conf
$ ./redis-server redis2.conf
$ ./redis-server redis3.conf
$ ./redis-server redis4.conf
$ ./redis-server redis5.conf
$ ./redis-server redis6.conf
#클러스터 연결
$ redis-cli --cluster create 127.0.0.1:8000 127.0.0.1:8001 127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005 --cluster-replicas 1 --cluster-yes
#클러스터 연결 확인
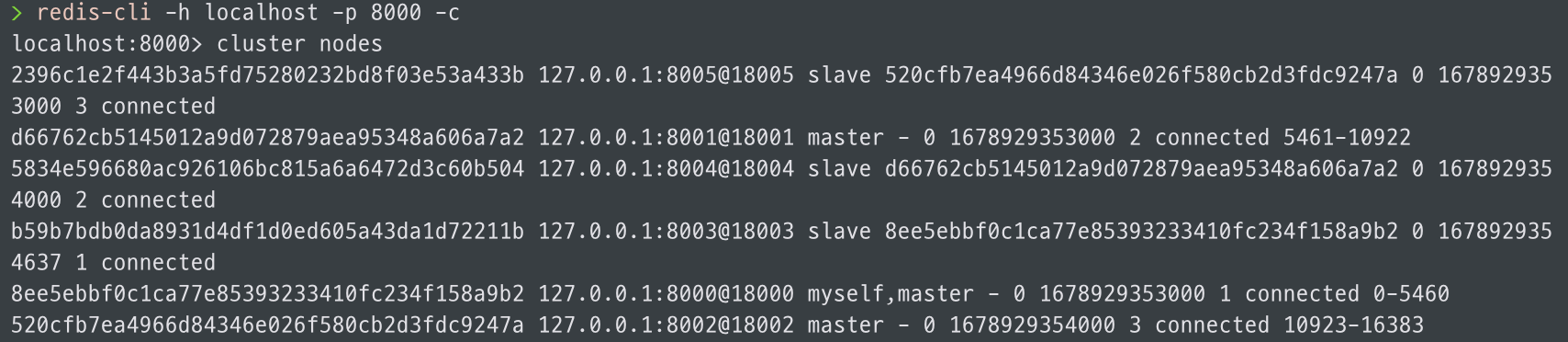
redis-cli > cluster nodes Cluster 연결이 완료되었으면 아래와 같은 결과가 나타납니다.
이렇게 구성한 각각의 Cluster에는 개별적으로 접속하여 확인해 볼 수 있습니다.
$ redis-cli -c -p 8000 -h localhost- -c : cluster 옵션으로 접속
- -p : 포트 번호로 접속. 기본값은 6379
- -h : 호스트로 접속. 기본값은 127.0.0.1
Cluster를 띄운 후 각 프로젝트에서 Cluster에 연결하도록 Redis 설정을 변경해 준 뒤, Redis를 사용하는 기능이 정상적으로 동작하는지 확인해 봅니다.
failover test와 topology auto update
Redis Cluster 구조의 장점은 Master/Slave에 비해 가용성이 증대되었다는 것입니다. 장애 상황에서 유연하게 대처할 수 있는 것이 장점인데, 이 장점이 제대로 발휘가 되는지 확인해 볼 필요가 있습니다.
redis-cli > cluster nodes를 통해 어떤 것이 master node인지 확인해 볼 수 있습니다.

현재 node는 8000번 port로 접속하였고, 8000, 8001, 8002가 master로 할당되었음을 볼 수 있습니다.
master node 중 하나로 접속하여 shutdown을 통해 master node를 죽이고서도 제대로 동작하는지 확인해 보도록 합니다.

Master인 8000번이 fail되어 그 자리를 slave였던 8003번이 master로 승격하여 빈자리를 채워주고 있지만 역부족이었습니다. 클라이언트 코드에서 500 에러를 뱉는 것을 볼 수 있습니다.
이는 클라이언트에서 변경된 master를 인지하지 못해 발생한 오류로, master와 slave가 변경될 경우 이를 업데이트해 주는 작업이 필요합니다.
lettuce.io에서는 ClusterTopologyRefreshOptions를 통해 cluster의 topology auto update를 지원하고 있습니다.
ClusterTopologyRefreshOptions를 사용하여 아래와 같이 RedisConnectionFactory를 세팅해 줍니다.
public RedisConnectionFactory connectionFactory() throws JSONException, SSLException {
// 클러스터 호스트 세팅
RedisClusterConfiguration redisClusterConfiguration = new RedisClusterConfiguration("Redis Cluster의 host 정보");
// topology 자동 업데이트 옵션 추가
// enablePeriodicRefresh(tolpology 정보 감시 텀) default vaule : 60s
ClusterTopologyRefreshOptions clusterTopologyRefreshOptions = ClusterTopologyRefreshOptions.builder()
.enableAllAdaptiveRefreshTriggers() // MOVED, ASK, PERSISTENT_RECONNECTS, UNCOVERED_SLOT, UNKOWN_NODE trigger시 refresh 진행
.build();
ClientOptions clientOptions = ClusterClientOptions.builder()
.topologyRefreshOptions(clusterTopologyRefreshOptions)
.build();
// topology 옵션 및 timeout 세팅
LettuceClientConfiguration clientConfiguration = LettuceClientConfiguration.builder()
.commandTimeout("timeout Duration값")
.clientOptions(clientOptions)
.build();
return new LettuceConnectionFactory(redisClusterConfiguration, clientConfiguration);
}코드 수정 후 동일하게 테스트를 진행해 봅니다.
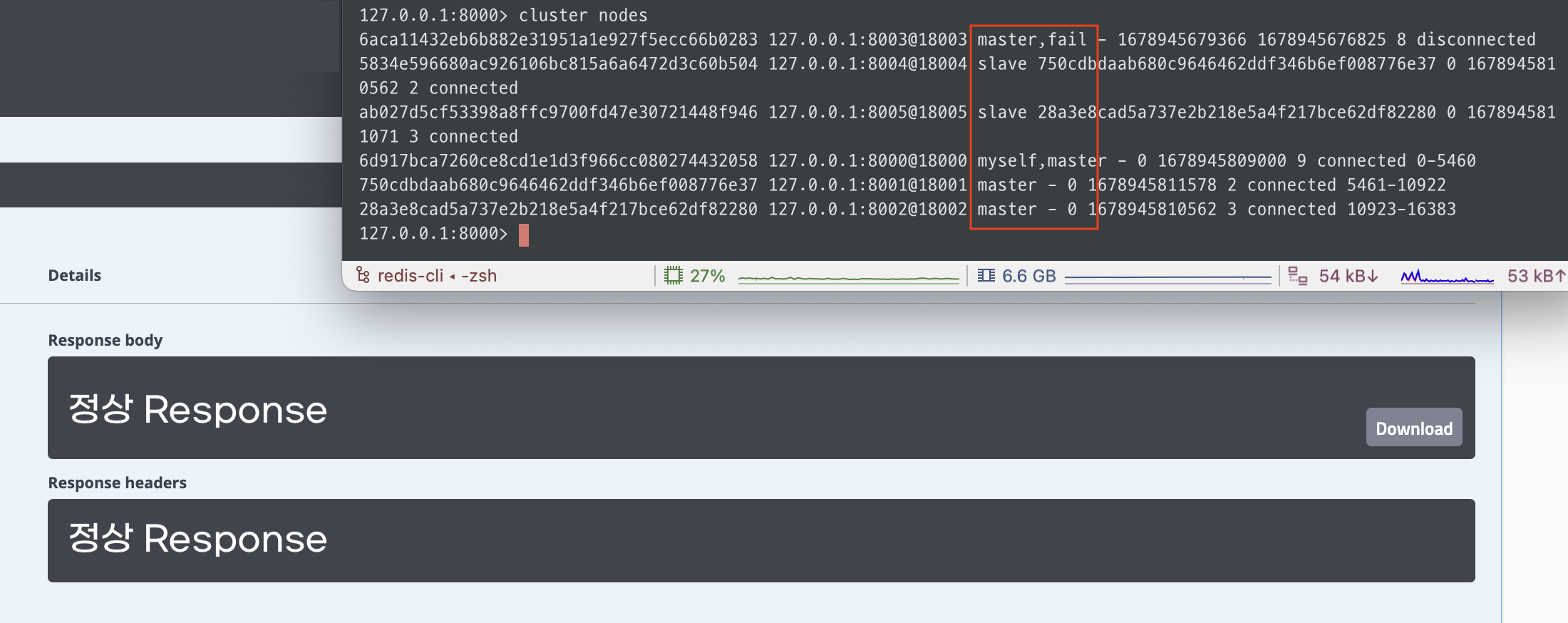
아까 master가 되었던 8003을 다시 돌려보내고 8000번이 master가 된 상황입니다. 기존 master가 fail하더라도 정상 Response를 받는 것을 확인할 수 있습니다.
맺음말
Redis의 R자도 모르는 상태에서 Cluster migration 작업을 진행하는 과정은 몹시 어려웠습니다. Redis에 대해 알기 위해 공식 문서를 수없이 펼쳐보고(그래서 그런지 본문 내에 공식 문서 링크가 빈번하게 등장하는 것 같습니다), 사내 위키 검색과 구글링은 끝나지 않아 인터넷 브라우저 탭이 닫히지 않고 늘어나기만 했으며, cli와 docker도 계속해서 들락날락했던 것 같습니다.
서론에서 말씀드렸듯이 저 혼자서는 진행할 수 없었던 작업이라 생각합니다. 사내 위키를 작성해 주신 많은 기여자분과 이슈가 생기면 옆에서 친절하게 알려 주셨던 동료들 덕에 작업을 무사히 진행할 수 있었다고 생각합니다.
작업을 진행할 때는 앞서 말씀드렸던 이슈 외에도 굉장히 많은 이슈들이 발생했습니다. Spring Boot 버전 문제와 사내 솔루션 문제 등, 이 작업을 진행하실 다른 분들도 이 외에 많은 이슈들이 추가로 발생하리라 생각합니다. 그래서 예상했던 것 보다 훨씬 작업이 오래 걸릴 수 있다는 점도 염두에 두셨으면 합니다.
잘못된 정보나 보충해야 할 정보가 있다면 댓글 남겨주시면 참고하도록 하겠습니다.
부족하지만 긴 글 읽어주셔서 감사드립니다. 다음에 더 좋은 글로 찾아오도록 하겠습니다 🙂
'Backend' 카테고리의 다른 글
| BigDecimal A to Z: 정확한 계산을 위한 숫자 처리 클래스 (0) | 2023.04.19 |
|---|---|
| docker-compose를 이용하여 로컬 개발환경 구성하기(Part1) (2) | 2023.04.12 |
| Redis Lua Script를 이용해서 API Rate Limiter개발 (4) | 2023.03.16 |
| Java Logger의 또다른 식구, tinylog (0) | 2023.03.02 |
| Handling-request-binding-exception in webflux (0) | 2023.02.15 |